联邦学习
移动算法和模型,而不是数据
联邦学习是一种分布式的机器学习,其目标是在数据高度分散于不同的服务器节点,无法实现有效交互的情况下,训练出高质量的模型。
传统的机器学习技术存在泄露病患数据隐私的风险,这阻碍了人工智能在医疗健康和生命科学领域的广泛应用。
联邦学习是一种正在兴起的新技术,旨在通过本地化训练确保数据不离开源头,从而保护隐私。与此同时,各节点共享不包含任何隐私数据的训练结果完成模型训练。
对于拥有海量数据的医疗健康及生命科学研究机构而言,机器学习技术的出现将帮助它们充分发掘手中数据的价值,为病患提供更加有效的治疗方案。
什么是联邦学习 ?

基于大数据的机器学习已经成为人工智能领域最具潜力的研究方向。通过机器学习,可以对现代医疗健康系统中的海量医疗数据进行提炼并构建出精确、稳健的统计学预测模型。当前,各个医疗机构的数据相互孤立, 并且出于隐私保护,数据的访问严格受限。因此,大量医疗数据的价值尚无法通过机器学习得到充分的挖掘。与此同时,数据访问受限也将阻碍机器学习的潜力得到完全释放。
假设你的任务是创建一个机器学习应用程序,该应用程序需要针对用户敏感数据进行自主训练。 你从许多用户那里合规的提取和整合了数据,并将它们放入在集中式云服务器上,用于机器学习模型的训练。
机器学习
数据需要被上传到中央服务器对模型进行训练
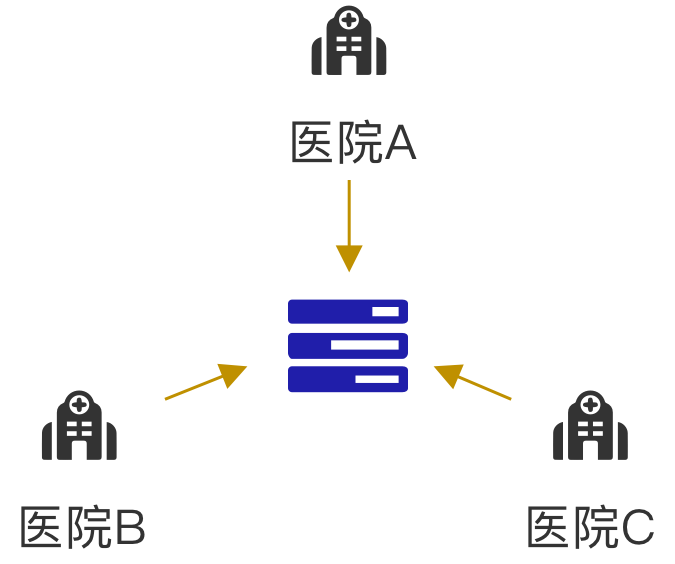
解决方案
如果我们不获取用户的敏感数据,而是在每个节点上本地训练我们的数据模型会怎样?
实现方法:在本地节点而非中央服务器,对模型进行训练,避免隐私数据泄露!在某个特定节点上产生的用户数据,将被作为该节点的本地数据, 用来更加高效快速地训练模型。训练完成后,本地节点与中央服务器交换训练结果,而非用户数据。
总结
对于类似医疗健康这类对病患隐私及数据安全有着极为严格要求的行业而言,能够实现跨医院和医疗机构的大规模机器学习模型训练, 而无需对数据进行转移的联邦学习技术是至关重要的。利用联邦学习技术,数据科学家、医疗专家以及数据管理人员可以共同协作,进行预测模型的训练。
联邦学习的主要目标是从各个参与方彼此相互孤立的数据中提取出关键知识,整合到一个全局模型中。

联邦学习
数据不离开本地节点,仅对模型进行同步更新
